|
本文主要針對Java 堆內(nèi)存劃分,,GC垃圾回收做一個簡單的介紹 1:首先說一下確認對象死亡的方法有: a:引用計數(shù)法--- 一個對象每被一個對象引用計數(shù)+1 ,。 b:可達性分析法--- 從GC ROOT往下索引能夠索引到該對象則表示可達,即該對象依然有被引用到,,表示存活 2:回收算法有: a:標記-清除法 ,,即標記出死亡的對象,然后將標記的對象直接回收掉,。優(yōu)點在于快,,缺點在于制造出很多的內(nèi)存碎片,有可能造成進行大對象時沒有連續(xù)空間分配而導致再次GC,。
b:復制算法:例如將內(nèi)存分為兩塊,,其中一塊用于分配內(nèi)存來存儲對象,另一部分空著,。在GC的時候確認哪些對象存活的,,把它們移到另外一塊內(nèi)存區(qū)域中,然后將原先那塊內(nèi)存全部回收,。這樣的好處就是沒有了內(nèi)存碎片且相對高效,,缺點就是內(nèi)存變小了一半
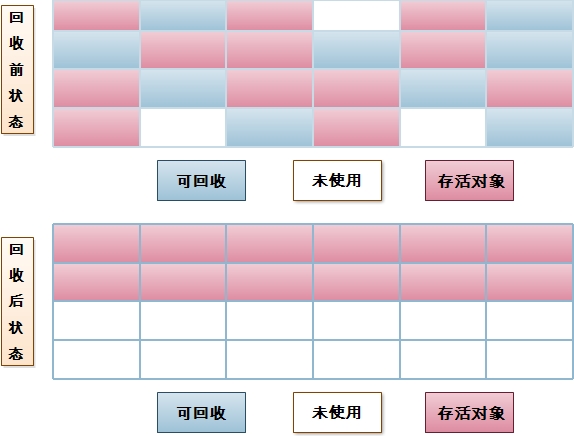
c:標記-清理:將存活的對象移動到一端,然后記錄邊際區(qū)域,,對邊際區(qū)域外的內(nèi)存進行回收,。好處在于不生成碎片,壞處在于成本比較高,。
3:堆內(nèi)存被粗略的劃分為新生代跟老年代,,如圖所示,Eden區(qū)跟TO,FROM區(qū)統(tǒng)稱為新生代,,默認情況下Eden:TO:FROM = 8 : 1 : 1,,可通過參數(shù)配置。Old則表示老年代
絕大多數(shù)對象被實例化的時候都會分配在Eden區(qū)(某些大對象直接分配到Old區(qū),,可通過參數(shù)設置限制值),。因為絕大多數(shù)的對象都是朝夕朝滅,,在使用一次后很快就死亡的。所以新生代區(qū)使用的是復制算法進行垃圾回收,,當發(fā)生一次GC時Eden跟FROM(或者TO)中存活的對象會移動到TO(或者FROM)中,,然后對Eden跟FROM(或者TO)中的內(nèi)存進行回收。當TO中的內(nèi)存不夠存放存活對象時則會將他們轉移到OLD中,。 當對象在新生代中經(jīng)過多次GC(默認好像是10次)后依然存活則會將其轉移到老年代,。老年代中使用的回收算法有標記-清理跟標記-清除,主要看收集器的實現(xiàn),。
4:新生代收集器 a :serial收集器:單線程,,需要stop the world(即回收的時候其他線程都必須暫停) b :parNew :可以看做是serial的多線程版本~在多CPU環(huán)境下性能會高于serial,但是少CPU環(huán)境下性能反而低于serial,,比較牽扯到各種線程間的調(diào)用 c :Parallel Scavenge :多線程并發(fā)的收集器,,跟serial,parNew這些以減少停頓時間為目的的收集器不同,,它專注于提高系統(tǒng)吞吐量 5:老年代收集器 a:serial old:使用標記-清理 b:Parallel old :專注吞吐量 c:CMS:使用標記-清除算法,,一個比較牛掰的收集器。CMS收集器分4個步驟:1,,初始標記 2,,并發(fā)標記 3,,重新標記 4,,并發(fā)清除 耗時最長的并發(fā)標記和并發(fā)清除都可以與用戶線程一起工作了。 還有三個缺點:1,,對cpu資源敏感,,默認啟動的回收線程數(shù)是(cpu數(shù)量+3)/4,當cpu數(shù)較少的時候,,會分掉大部分的cpu去執(zhí)行收集器線程,,影響用戶,降低吞吐量,。 2,,無法處理浮動垃圾,浮動垃圾即在并發(fā)清除階段因為是并發(fā)執(zhí)行,,還會產(chǎn)生垃圾,,這一部分垃圾即為浮動垃圾,要等下次收集,。3,因為使用的是“標記-清除”算法,,會產(chǎn)生碎片 6:橫跨新生代與老年代的收集器-----G1(Grabage First):基于標記-清理。比較復雜,,還不是很懂~
上圖中收集器間的連線表示兩個收集器能配合使用,,一個用于新生代,,一個用于老年代。G1則能自己包辦兩個代~
在代碼開發(fā)中需要注意:千萬不要實例化朝夕朝滅的大對象,,比如new byte[1024*1024*20]這樣一口氣就實例化一個20m的對象,,然后用一次后就不需要的。因為老年代中對象回收相對性能比新生代的低,,所以這樣做會嚴重影響性能
|
|
|